Using a Rank Over a Partition When Working with Transactional SQL Tables

You will often encounter a transactional table in a SQL database. This is a table that typically is only inserted into. A good example is a bank account ledger where every transaction you make is recorded as a new row.
What makes these tables a challenge is easily finding the top "X" for each "Y" in the table. The easiest method I've found is to use a RANK over a PARTITION.
We will look at an example for a video game where the database has a table designed to save the results of each game played. So, every time the game is played we will see a single row added to the table that tells us who played and what score they received along with a timestamp for the event.
Here is some code to create such a table.
CREATE TABLE gameScores (
playerId INT,
gamePlayedAt DATETIME,
score INT
) Now, insert some example data.
INSERT INTO gameScores (playerId, gamePlayedAt, score)
VALUES
(3, DATE_SUB(CURRENT_TIMESTAMP, INTERVAL 1 DAY), 23),
(2, DATE_SUB(CURRENT_TIMESTAMP, INTERVAL 1 DAY), 44),
(3, DATE_SUB(CURRENT_TIMESTAMP, INTERVAL 2 DAY), 22),
(4, DATE_SUB(CURRENT_TIMESTAMP, INTERVAL 2 DAY), 17),
(5, DATE_SUB(CURRENT_TIMESTAMP, INTERVAL 2 DAY), 27),
(2, DATE_SUB(CURRENT_TIMESTAMP, INTERVAL 3 DAY), 29),
(1, DATE_SUB(CURRENT_TIMESTAMP, INTERVAL 3 DAY), 46),
(2, DATE_SUB(CURRENT_TIMESTAMP, INTERVAL 4 DAY), 21),
(3, DATE_SUB(CURRENT_TIMESTAMP, INTERVAL 4 DAY), 10),
(4, DATE_SUB(CURRENT_TIMESTAMP, INTERVAL 4 DAY), 49),
(3, DATE_SUB(CURRENT_TIMESTAMP, INTERVAL 4 DAY), 33),
(5, DATE_SUB(CURRENT_TIMESTAMP, INTERVAL 5 DAY), 84),
(2, DATE_SUB(CURRENT_TIMESTAMP, INTERVAL 5 DAY), 73),
(3, DATE_SUB(CURRENT_TIMESTAMP, INTERVAL 5 DAY), 79),
(1, DATE_SUB(CURRENT_TIMESTAMP, INTERVAL 5 DAY), 42)Lets say we're interested in answering the following question:
- What is the score each player earned the last time they played?
The answer can be found easily with a RANK over a PARTITION. What does this mean? First imagine the data sorted by each playerId and then by the time the game was played (gamePlayedAt).
SELECT
playerId,
gamePlayedAt,
score
FROM gameScores
ORDER BY playerId ASC, gamePlayedAt DESC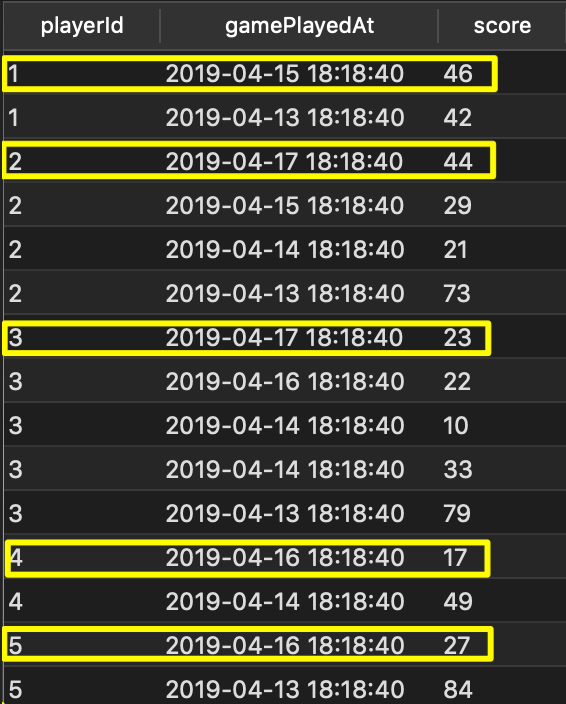
We can see the answer in the results, but there are a lot more rows than we actually need. We really need the highlighted rows only. How do we tell the SQL server that this is what we want? Easy! Tell it how to group the data and how to rank the rows in each of those groups.
So, for this example we would PARTITION by the playerId, then RANK those partitions by the gamePlayedAt. Since we want the more recent records first, we will specify the order to be descending.
Here is how that would look:
WITH scores AS (
SELECT
*,
RANK() OVER (PARTITION BY playerId ORDER BY gamePlayedAt DESC) AS rnk
FROM gameScores
)
SELECT
playerId,
gamePlayedAt,
score
FROM scores
WHERE rnk = 1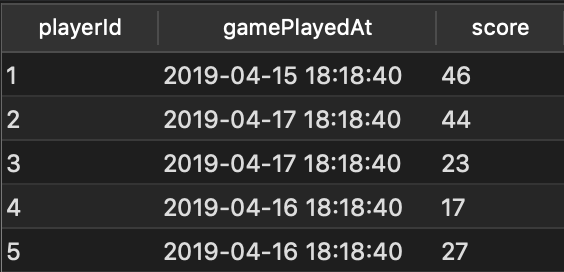
And these are only the rows that we had highlighted from the full list of scores!
Lets answer another very similar question:
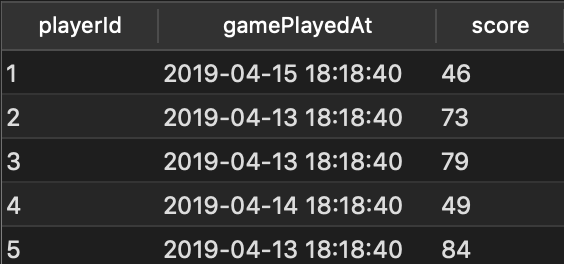
- What is the highest score each player has ever earned?
To answer this, we again partition by the playerId. What is different is which column we tell SQL Server to sort (order) by. The query is nearly identical. The only difference is the column specified after the ORDER BY.
WITH scores AS (
SELECT
*,
RANK() OVER (PARTITION BY playerId ORDER BY score DESC) AS rnk
FROM gameScores
)
SELECT
playerId,
gamePlayedAt,
score
FROM scores
WHERE rnk = 1
You will find many other uses for a RANK over a PARTITION. Generally, any time you're looking at a dataset where you have multiple records for similar things, you may want to consider this type of strategy. Especially if want to sort on a single column and get the first row, or first few rows, for each of those things.
